

In the heart of the artificial intelligence revolution, behind every smart algorithm and predictive model, lies a critical and often unseen human endeavor. This is the domain of the global Data Annotation And Labelling industry, a sector that serves as the essential preparatory school for machine learning. Data annotation is the meticulous process of adding metadata, or labels, to raw data—such as images, text, audio, and video—to make it understandable and useful for AI models. In essence, it is the process of teaching a computer how to perceive the world. For an AI to learn to identify a cat, it must first be shown thousands of images explicitly labeled as "cat." This labeled data is the fuel for supervised machine learning, the most common form of AI today. Without high-quality, accurately labeled training data, even the most sophisticated algorithms are effectively blind and useless. This industry, therefore, is not just a support function; it is the foundational, indispensable prerequisite for the development and deployment of nearly all modern AI applications, from self-driving cars to medical diagnostic tools.
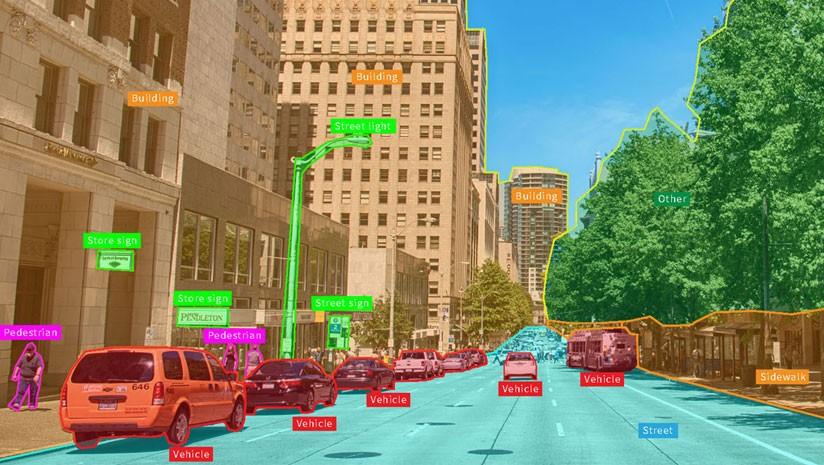
The most visible and widely understood application of data annotation is in the field of computer vision. For an autonomous vehicle to navigate a street safely, its AI model must be able to instantly identify and differentiate between pedestrians, other cars, traffic lights, and lane markings. This is achieved by training the model on millions of images and video frames that have been painstakingly annotated by humans. This can take several forms. Bounding boxes are the simplest, involving drawing a rectangle around an object of interest. More complex is polygon annotation, where annotators trace the precise outline of an object, which is crucial for irregularly shaped items. The most granular form is semantic segmentation, where every single pixel in an image is assigned a class label (e.g., this pixel is 'road,' this pixel is 'sky,' this pixel is 'tree'). Another key type is keypoint annotation, used to identify specific points of interest, such as the joints on a human body for pose estimation or facial landmarks for emotion recognition. The accuracy and consistency of this visual data annotation directly determine the safety and reliability of the resulting computer vision model.
Beyond images and video, the industry is equally vital for the development of Natural Language Processing (NLP) and speech recognition technologies. For a chatbot or virtual assistant to understand a user's request, its underlying NLP model must be trained on vast amounts of annotated text. Named Entity Recognition (NER) is a common task, where annotators highlight and label key entities in a body of text, such as 'person,' 'organization,' 'location,' or 'date.' Sentiment analysis involves labeling text (like a product review or a social media post) as 'positive,' 'negative,' or 'neutral,' which is crucial for brand monitoring and customer feedback analysis. Text classification involves categorizing entire documents into predefined topics, such as labeling news articles as 'sports,' 'politics,' or 'finance.' For speech recognition, audio files are transcribed and time-stamped, allowing an AI to learn the association between spoken sounds and written words. This linguistic annotation is the fundamental process that enables machines to comprehend, interpret, and respond to human language in a meaningful way, powering everything from smart speakers to automated customer service systems.
To meet the immense demand for this labeled data, the industry operates through several distinct business models. The first is the use of in-house teams, where a company hires and manages its own team of annotators. This model provides the highest level of control over quality and data security but can be difficult and expensive to scale. The second is crowdsourcing, which leverages massive, distributed online workforces through platforms like Amazon Mechanical Turk. This model is excellent for scaling simple, high-volume tasks at a low cost but can present challenges in maintaining consistent quality and is not suitable for tasks requiring specialized expertise or handling sensitive data. The third and fastest-growing model is the use of managed service providers. These specialized companies, like Scale AI or Appen, offer a full-service, "data-as-a-service" solution. They combine their proprietary software platforms with a curated, trained, and managed workforce to deliver high-quality, project-ready labeled data to their clients. This model provides a balance of scale, quality, and expertise, making it the preferred choice for many large enterprises with complex, ongoing AI initiatives.
Top Trending Reports:
Fraud Detection and Prevention Market